> ## Documentation Index
> Fetch the complete documentation index at: https://docs.firecrawl.dev/llms.txt
> Use this file to discover all available pages before exploring further.
# Firecrawl MCP Server
> Use Firecrawl's API through the Model Context Protocol
A Model Context Protocol (MCP) server implementation that integrates [Firecrawl](https://github.com/firecrawl/firecrawl) for searching, scraping, and interacting with the web. Our MCP server is open-source and available on [GitHub](https://github.com/firecrawl/firecrawl-mcp-server).
## Features
* Search the web and get full page content
* Scrape any URL into clean, structured data
* Parse local files such as PDFs, DOCX, XLSX, and HTML
* Interact with pages — click, navigate, and operate
* Deep research with autonomous agent
* Cloud and self-hosted support
* Streamable HTTP support
## Installation
You can either use our remote hosted URL or run the server locally. Get your API key from [https://firecrawl.dev/app/api-keys](https://www.firecrawl.dev/app/api-keys)
**No API key?** Connect to `https://mcp.firecrawl.dev/v2/mcp` to use the remote keyless free tier. It is free and rate-limited per IP; see [Rate Limits](/rate-limits#keyless-no-api-key) for the current keyless tool list. Set `FIRECRAWL_API_KEY` to unlock every MCP tool plus higher limits.
### Remote hosted URL
With an API key (unlocks every tool plus higher limits):
```bash theme={null}
https://mcp.firecrawl.dev/{FIRECRAWL_API_KEY}/v2/mcp
```
Or connect without an API key to get started on the remote keyless free tier (rate-limited per IP; see [Rate Limits](/rate-limits#keyless-no-api-key) for the current tool list):
```bash theme={null}
https://mcp.firecrawl.dev/v2/mcp
```
### Running with npx
```bash theme={null}
env FIRECRAWL_API_KEY=fc-YOUR_API_KEY npx -y firecrawl-mcp
```
### Manual Installation
```bash theme={null}
npm install -g firecrawl-mcp
```
### Running on Cursor
 #### Manual Installation
Configuring Cursor 🖥️
Note: Requires Cursor version 0.45.6+
For the most up-to-date configuration instructions, please refer to the official Cursor documentation on configuring MCP servers:
[Cursor MCP Server Configuration Guide](https://docs.cursor.com/context/model-context-protocol#configuring-mcp-servers)
To configure Firecrawl MCP in Cursor **v0.48.6**
1. Open Cursor Settings
2. Go to Features > MCP Servers
3. Click "+ Add new global MCP server"
4. Enter the following code:
```json theme={null}
{
"mcpServers": {
"firecrawl-mcp": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR-API-KEY"
}
}
}
}
```
To configure Firecrawl MCP in Cursor **v0.45.6**
1. Open Cursor Settings
2. Go to Features > MCP Servers
3. Click "+ Add New MCP Server"
4. Enter the following:
* Name: "firecrawl-mcp" (or your preferred name)
* Type: "command"
* Command: `env FIRECRAWL_API_KEY=your-api-key npx -y firecrawl-mcp`
> If you are using Windows and are running into issues, try `cmd /c "set FIRECRAWL_API_KEY=your-api-key && npx -y firecrawl-mcp"`
Replace `your-api-key` with your Firecrawl API key. If you don't have one yet, you can create an account and get it from [https://www.firecrawl.dev/app/api-keys](https://www.firecrawl.dev/app/api-keys)
After adding, refresh the MCP server list to see the new tools. The Composer Agent will automatically use Firecrawl MCP when appropriate, but you can explicitly request it by describing your web data needs. Access the Composer via Command+L (Mac), select "Agent" next to the submit button, and enter your query.
### Running on Windsurf
Add this to your `./codeium/windsurf/model_config.json`:
```json theme={null}
{
"mcpServers": {
"mcp-server-firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR_API_KEY"
}
}
}
}
```
### Running with Streamable HTTP Mode
To run the server using streamable HTTP transport locally instead of the default stdio transport:
```bash theme={null}
env HTTP_STREAMABLE_SERVER=true FIRECRAWL_API_KEY=fc-YOUR_API_KEY npx -y firecrawl-mcp
```
Use the url: [http://localhost:3000/v2/mcp](http://localhost:3000/v2/mcp) or [https://mcp.firecrawl.dev/\{FIRECRAWL\_API\_KEY}/v2/mcp](https://mcp.firecrawl.dev/\{FIRECRAWL_API_KEY}/v2/mcp)
### Installing via Smithery (Legacy)
To install Firecrawl for Claude Desktop automatically via [Smithery](https://smithery.ai/server/@mendableai/mcp-server-firecrawl):
```bash theme={null}
npx -y @smithery/cli install @mendableai/mcp-server-firecrawl --client claude
```
### Running on VS Code
For one-click installation, click one of the install buttons below\...
[](https://insiders.vscode.dev/redirect/mcp/install?name=firecrawl\&inputs=%5B%7B%22type%22%3A%22promptString%22%2C%22id%22%3A%22apiKey%22%2C%22description%22%3A%22Firecrawl%20API%20Key%22%2C%22password%22%3Atrue%7D%5D\&config=%7B%22command%22%3A%22npx%22%2C%22args%22%3A%5B%22-y%22%2C%22firecrawl-mcp%22%5D%2C%22env%22%3A%7B%22FIRECRAWL_API_KEY%22%3A%22%24%7Binput%3AapiKey%7D%22%7D%7D) [](https://insiders.vscode.dev/redirect/mcp/install?name=firecrawl\&inputs=%5B%7B%22type%22%3A%22promptString%22%2C%22id%22%3A%22apiKey%22%2C%22description%22%3A%22Firecrawl%20API%20Key%22%2C%22password%22%3Atrue%7D%5D\&config=%7B%22command%22%3A%22npx%22%2C%22args%22%3A%5B%22-y%22%2C%22firecrawl-mcp%22%5D%2C%22env%22%3A%7B%22FIRECRAWL_API_KEY%22%3A%22%24%7Binput%3AapiKey%7D%22%7D%7D\&quality=insiders)
For manual installation, add the following JSON block to your User Settings (JSON) file in VS Code. You can do this by pressing `Ctrl + Shift + P` and typing `Preferences: Open User Settings (JSON)`.
```json theme={null}
{
"mcp": {
"inputs": [
{
"type": "promptString",
"id": "apiKey",
"description": "Firecrawl API Key",
"password": true
}
],
"servers": {
"firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "${input:apiKey}"
}
}
}
}
}
```
Optionally, you can add it to a file called `.vscode/mcp.json` in your workspace. This will allow you to share the configuration with others:
```json theme={null}
{
"inputs": [
{
"type": "promptString",
"id": "apiKey",
"description": "Firecrawl API Key",
"password": true
}
],
"servers": {
"firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "${input:apiKey}"
}
}
}
}
```
**Note:** Some users have reported issues when adding the MCP server to VS Code due to how it validates JSON with an outdated schema format ([microsoft/vscode#155379](https://github.com/microsoft/vscode/issues/155379)).
This affects several MCP tools, including Firecrawl.
**Workaround:** Disable JSON validation in VS Code to allow the MCP server to load properly.\
See reference: [directus/directus#25906 (comment)](https://github.com/directus/directus/issues/25906#issuecomment-3369169513).
The MCP server still works fine when invoked via other extensions, but the issue occurs specifically when registering it directly in the MCP server list. We plan to add guidance once VS Code updates their schema validation.
### Running on Claude Desktop
Add this to the Claude config file:
```json theme={null}
{
"mcpServers": {
"firecrawl": {
"url": "https://mcp.firecrawl.dev/v2/mcp",
"headers": {
"Authorization": "Bearer YOUR_API_KEY"
}
}
}
}
```
If you get a "Couldn't reach the MCP server" error, your Claude Desktop version may not support streamable HTTP transport. Use the local npx approach instead (requires [Node.js](https://nodejs.org)):
```json theme={null}
{
"mcpServers": {
"firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR_API_KEY"
}
}
}
}
```
If you see a `spawn npx ENOENT` error, Node.js is not installed or not in your system PATH. Install Node.js from [nodejs.org](https://nodejs.org) (LTS version), then fully restart Claude Desktop. On Windows, you can also run `where npx` in Command Prompt and use the full path (e.g. `C:\\Program Files\\nodejs\\npx.cmd`) as the `command` value.
### Running on Claude Code
Add the Firecrawl MCP server using the Claude Code CLI. You can use the remote hosted URL or run locally:
```bash theme={null}
# Remote hosted URL (recommended)
claude mcp add --transport http firecrawl https://mcp.firecrawl.dev/your-api-key/v2/mcp
# Or run locally via npx
claude mcp add firecrawl -e FIRECRAWL_API_KEY=your-api-key -- npx -y firecrawl-mcp
```
### Running on Google Antigravity
Google Antigravity allows you to configure MCP servers directly through its Agent interface.
#### Manual Installation
Configuring Cursor 🖥️
Note: Requires Cursor version 0.45.6+
For the most up-to-date configuration instructions, please refer to the official Cursor documentation on configuring MCP servers:
[Cursor MCP Server Configuration Guide](https://docs.cursor.com/context/model-context-protocol#configuring-mcp-servers)
To configure Firecrawl MCP in Cursor **v0.48.6**
1. Open Cursor Settings
2. Go to Features > MCP Servers
3. Click "+ Add new global MCP server"
4. Enter the following code:
```json theme={null}
{
"mcpServers": {
"firecrawl-mcp": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR-API-KEY"
}
}
}
}
```
To configure Firecrawl MCP in Cursor **v0.45.6**
1. Open Cursor Settings
2. Go to Features > MCP Servers
3. Click "+ Add New MCP Server"
4. Enter the following:
* Name: "firecrawl-mcp" (or your preferred name)
* Type: "command"
* Command: `env FIRECRAWL_API_KEY=your-api-key npx -y firecrawl-mcp`
> If you are using Windows and are running into issues, try `cmd /c "set FIRECRAWL_API_KEY=your-api-key && npx -y firecrawl-mcp"`
Replace `your-api-key` with your Firecrawl API key. If you don't have one yet, you can create an account and get it from [https://www.firecrawl.dev/app/api-keys](https://www.firecrawl.dev/app/api-keys)
After adding, refresh the MCP server list to see the new tools. The Composer Agent will automatically use Firecrawl MCP when appropriate, but you can explicitly request it by describing your web data needs. Access the Composer via Command+L (Mac), select "Agent" next to the submit button, and enter your query.
### Running on Windsurf
Add this to your `./codeium/windsurf/model_config.json`:
```json theme={null}
{
"mcpServers": {
"mcp-server-firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR_API_KEY"
}
}
}
}
```
### Running with Streamable HTTP Mode
To run the server using streamable HTTP transport locally instead of the default stdio transport:
```bash theme={null}
env HTTP_STREAMABLE_SERVER=true FIRECRAWL_API_KEY=fc-YOUR_API_KEY npx -y firecrawl-mcp
```
Use the url: [http://localhost:3000/v2/mcp](http://localhost:3000/v2/mcp) or [https://mcp.firecrawl.dev/\{FIRECRAWL\_API\_KEY}/v2/mcp](https://mcp.firecrawl.dev/\{FIRECRAWL_API_KEY}/v2/mcp)
### Installing via Smithery (Legacy)
To install Firecrawl for Claude Desktop automatically via [Smithery](https://smithery.ai/server/@mendableai/mcp-server-firecrawl):
```bash theme={null}
npx -y @smithery/cli install @mendableai/mcp-server-firecrawl --client claude
```
### Running on VS Code
For one-click installation, click one of the install buttons below\...
[](https://insiders.vscode.dev/redirect/mcp/install?name=firecrawl\&inputs=%5B%7B%22type%22%3A%22promptString%22%2C%22id%22%3A%22apiKey%22%2C%22description%22%3A%22Firecrawl%20API%20Key%22%2C%22password%22%3Atrue%7D%5D\&config=%7B%22command%22%3A%22npx%22%2C%22args%22%3A%5B%22-y%22%2C%22firecrawl-mcp%22%5D%2C%22env%22%3A%7B%22FIRECRAWL_API_KEY%22%3A%22%24%7Binput%3AapiKey%7D%22%7D%7D) [](https://insiders.vscode.dev/redirect/mcp/install?name=firecrawl\&inputs=%5B%7B%22type%22%3A%22promptString%22%2C%22id%22%3A%22apiKey%22%2C%22description%22%3A%22Firecrawl%20API%20Key%22%2C%22password%22%3Atrue%7D%5D\&config=%7B%22command%22%3A%22npx%22%2C%22args%22%3A%5B%22-y%22%2C%22firecrawl-mcp%22%5D%2C%22env%22%3A%7B%22FIRECRAWL_API_KEY%22%3A%22%24%7Binput%3AapiKey%7D%22%7D%7D\&quality=insiders)
For manual installation, add the following JSON block to your User Settings (JSON) file in VS Code. You can do this by pressing `Ctrl + Shift + P` and typing `Preferences: Open User Settings (JSON)`.
```json theme={null}
{
"mcp": {
"inputs": [
{
"type": "promptString",
"id": "apiKey",
"description": "Firecrawl API Key",
"password": true
}
],
"servers": {
"firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "${input:apiKey}"
}
}
}
}
}
```
Optionally, you can add it to a file called `.vscode/mcp.json` in your workspace. This will allow you to share the configuration with others:
```json theme={null}
{
"inputs": [
{
"type": "promptString",
"id": "apiKey",
"description": "Firecrawl API Key",
"password": true
}
],
"servers": {
"firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "${input:apiKey}"
}
}
}
}
```
**Note:** Some users have reported issues when adding the MCP server to VS Code due to how it validates JSON with an outdated schema format ([microsoft/vscode#155379](https://github.com/microsoft/vscode/issues/155379)).
This affects several MCP tools, including Firecrawl.
**Workaround:** Disable JSON validation in VS Code to allow the MCP server to load properly.\
See reference: [directus/directus#25906 (comment)](https://github.com/directus/directus/issues/25906#issuecomment-3369169513).
The MCP server still works fine when invoked via other extensions, but the issue occurs specifically when registering it directly in the MCP server list. We plan to add guidance once VS Code updates their schema validation.
### Running on Claude Desktop
Add this to the Claude config file:
```json theme={null}
{
"mcpServers": {
"firecrawl": {
"url": "https://mcp.firecrawl.dev/v2/mcp",
"headers": {
"Authorization": "Bearer YOUR_API_KEY"
}
}
}
}
```
If you get a "Couldn't reach the MCP server" error, your Claude Desktop version may not support streamable HTTP transport. Use the local npx approach instead (requires [Node.js](https://nodejs.org)):
```json theme={null}
{
"mcpServers": {
"firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR_API_KEY"
}
}
}
}
```
If you see a `spawn npx ENOENT` error, Node.js is not installed or not in your system PATH. Install Node.js from [nodejs.org](https://nodejs.org) (LTS version), then fully restart Claude Desktop. On Windows, you can also run `where npx` in Command Prompt and use the full path (e.g. `C:\\Program Files\\nodejs\\npx.cmd`) as the `command` value.
### Running on Claude Code
Add the Firecrawl MCP server using the Claude Code CLI. You can use the remote hosted URL or run locally:
```bash theme={null}
# Remote hosted URL (recommended)
claude mcp add --transport http firecrawl https://mcp.firecrawl.dev/your-api-key/v2/mcp
# Or run locally via npx
claude mcp add firecrawl -e FIRECRAWL_API_KEY=your-api-key -- npx -y firecrawl-mcp
```
### Running on Google Antigravity
Google Antigravity allows you to configure MCP servers directly through its Agent interface.
 1. Open the Agent sidebar in the Editor or the Agent Manager view
2. Click the "..." (More Actions) menu and select **MCP Servers**
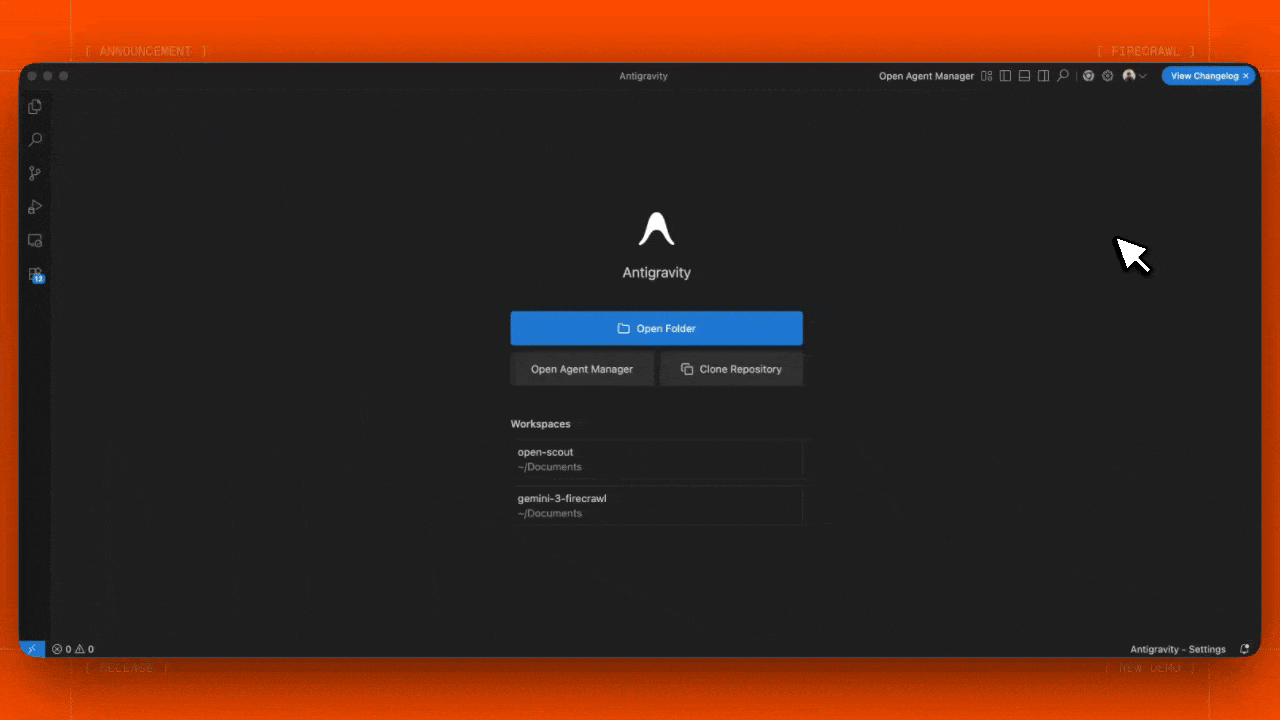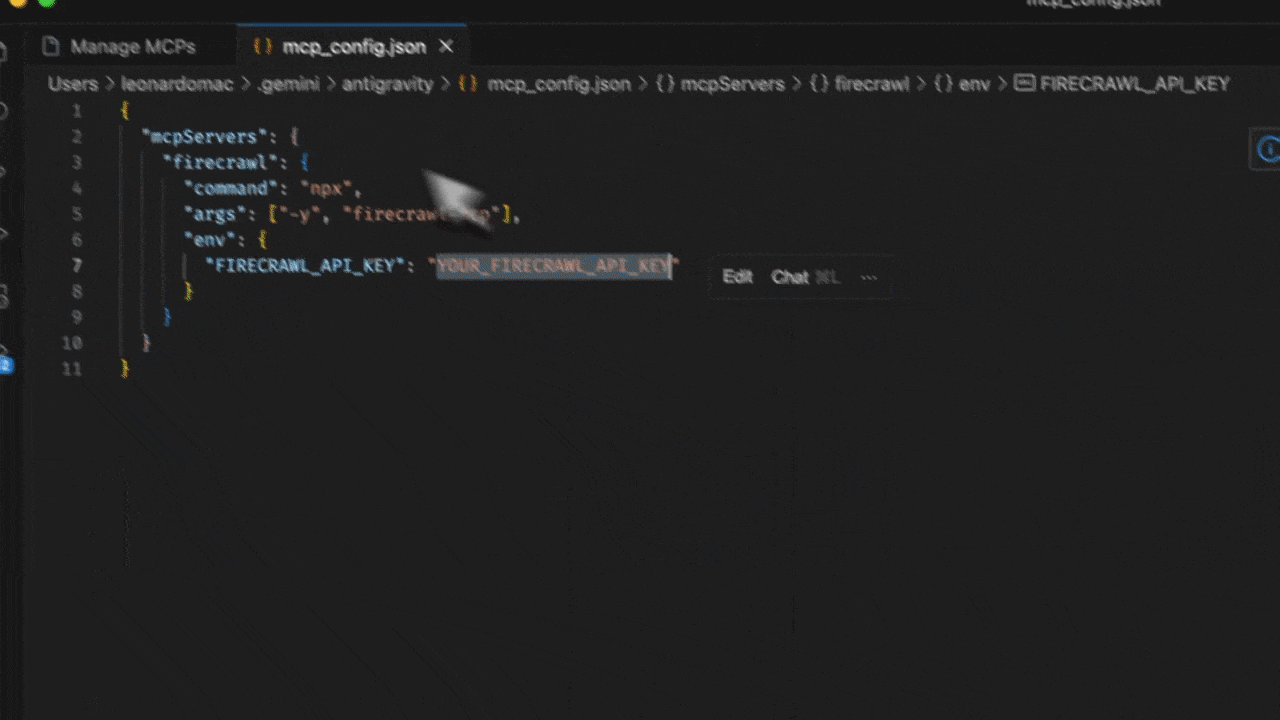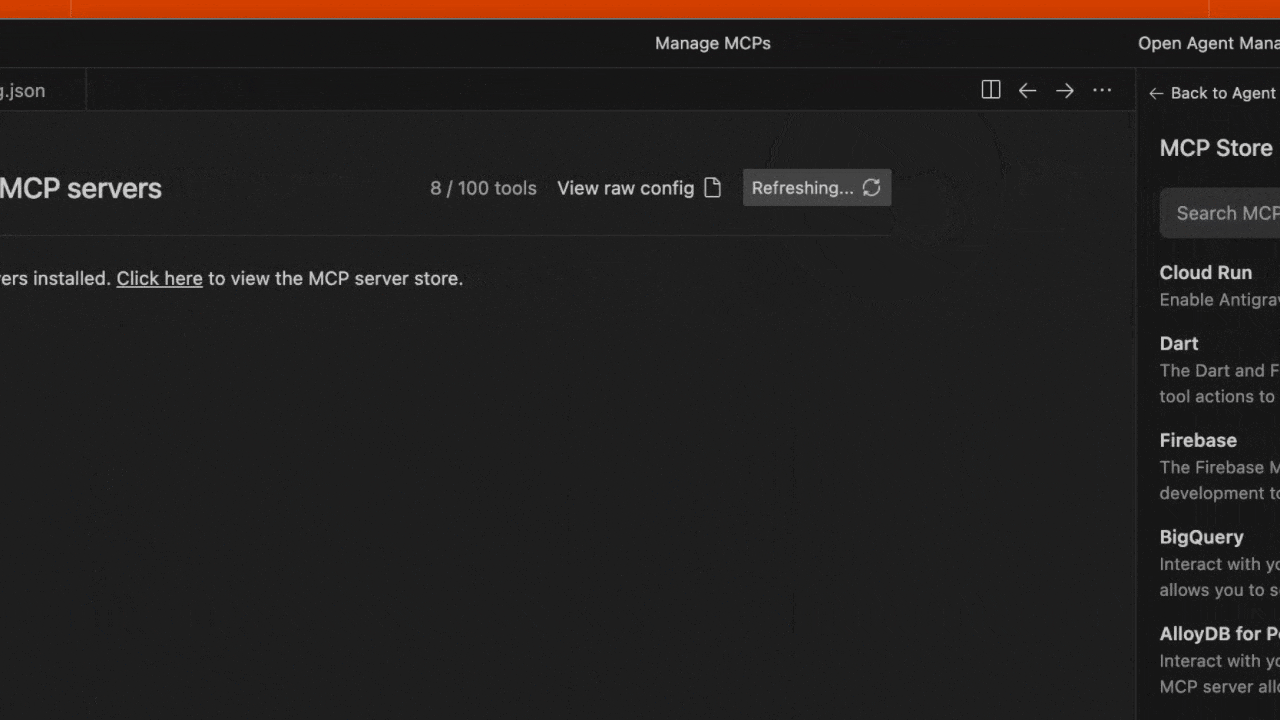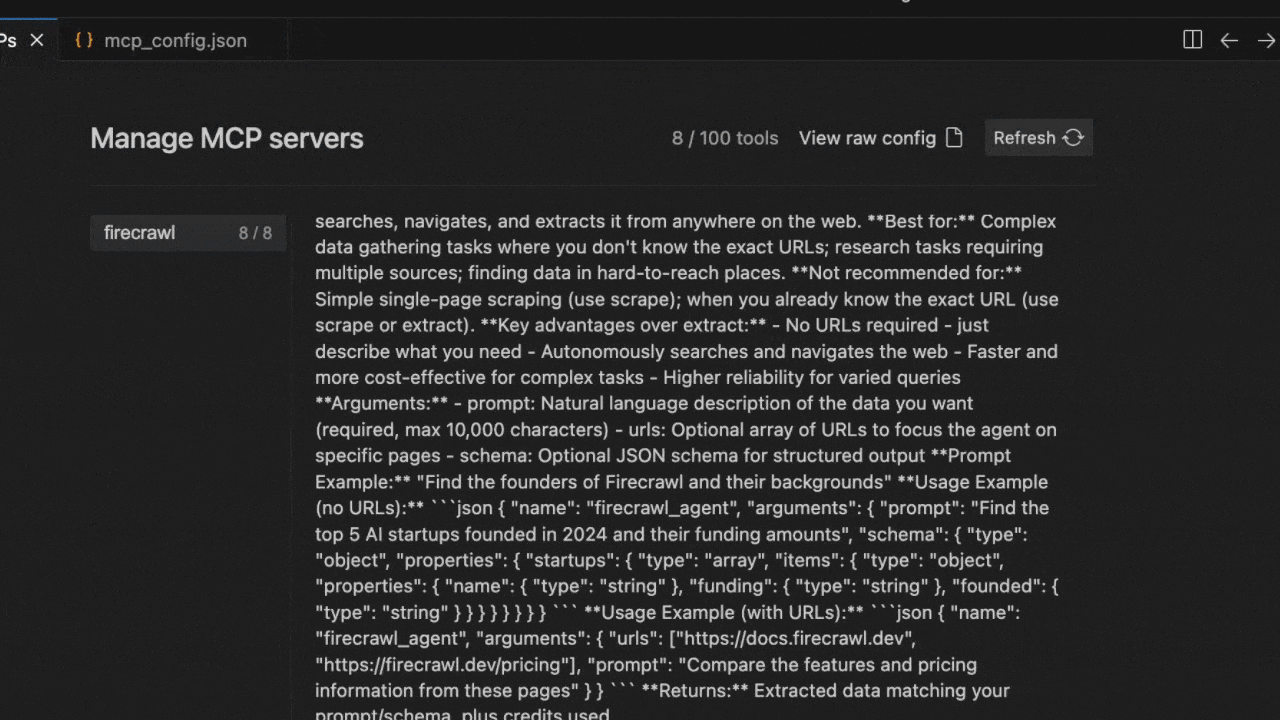
3. Select **View raw config** to open your local `mcp_config.json` file
4. Add the following configuration:
```json theme={null}
{
"mcpServers": {
"firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR_FIRECRAWL_API_KEY"
}
}
}
}
```
5. Save the file and click **Refresh** in the Antigravity MCP interface to see the new tools
Replace `YOUR_FIRECRAWL_API_KEY` with your API key from [https://firecrawl.dev/app/api-keys](https://www.firecrawl.dev/app/api-keys).
### Running on n8n
To connect the Firecrawl MCP server in n8n:
1. Get your Firecrawl API key from [https://firecrawl.dev/app/api-keys](https://www.firecrawl.dev/app/api-keys)
2. In your n8n workflow, add an **AI Agent** node
3. In the AI Agent configuration, add a new **Tool**
4. Select **MCP Client Tool** as the tool type
5. Enter the MCP server Endpoint (replace `{YOUR_FIRECRAWL_API_KEY}` with your actual API key):
```
https://mcp.firecrawl.dev/{YOUR_FIRECRAWL_API_KEY}/v2/mcp
```
6. Set **Server Transport** to **HTTP Streamable**
7. Set **Authentication** to **None**
8. For **Tools to include**, you can select **All**, **Selected**, or **All Except** - this will expose the Firecrawl tools (scrape, crawl, map, search, extract, etc.)
For self-hosted deployments, run the MCP server with npx and enable HTTP transport mode:
```bash theme={null}
env HTTP_STREAMABLE_SERVER=true \
FIRECRAWL_API_KEY=fc-YOUR_API_KEY \
FIRECRAWL_API_URL=YOUR_FIRECRAWL_INSTANCE \
npx -y firecrawl-mcp
```
This will start the server on `http://localhost:3000/v2/mcp` which you can use in your n8n workflow as Endpoint. The `HTTP_STREAMABLE_SERVER=true` environment variable is required since n8n needs HTTP transport.
## Configuration
### Environment Variables
#### Cloud and self-hosted API
* `FIRECRAWL_API_KEY`: Your Firecrawl API key
* Required when using cloud API (default)
* Optional when using self-hosted instance with `FIRECRAWL_API_URL`
* `FIRECRAWL_API_URL` (Optional): Custom API endpoint for self-hosted instances
* Example: `https://firecrawl.your-domain.com`
* If not provided, the cloud API will be used (requires API key)
### Configuration Examples
For cloud API usage:
```bash theme={null}
export FIRECRAWL_API_KEY=your-api-key
```
For self-hosted instance:
```bash theme={null}
export FIRECRAWL_API_URL=https://firecrawl.your-domain.com
export FIRECRAWL_API_KEY=your-api-key # If your instance requires auth
```
### Custom configuration with Claude Desktop
Add this to your `claude_desktop_config.json`:
```json theme={null}
{
"mcpServers": {
"mcp-server-firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR_API_KEY_HERE"
}
}
}
}
```
### Hosted MCP vs local MCP
The hosted MCP server is optimized for safe remote use. Some options that are available when running the MCP server locally are narrowed or unavailable remotely:
* Hosted keyless mode exposes only the keyless-supported tools and is rate-limited per IP.
* Local-only file reads are available only when you run the MCP server locally.
* Webhooks and local file paths should be configured from a local or self-hosted MCP server when the agent needs access to local resources.
### Rate Limiting
Rate limits are enforced by Firecrawl. Use an API key for higher limits and access to the full tool set.
## Available Tools
### 1. Scrape Tool (`firecrawl_scrape`)
Scrape content from a single URL with advanced options.
```json theme={null}
{
"name": "firecrawl_scrape",
"arguments": {
"url": "https://example.com",
"formats": ["markdown"],
"onlyMainContent": true,
"waitFor": 1000,
"mobile": false,
"includeTags": ["article", "main"],
"excludeTags": ["nav", "footer"],
"skipTlsVerification": false
}
}
```
To redact personally identifiable information, include `redactPII` in the scrape tool arguments.
```json theme={null}
{
"name": "firecrawl_scrape",
"arguments": {
"url": "https://example.com/contact",
"formats": ["markdown"],
"redactPII": true
}
}
```
### 2. Map Tool (`firecrawl_map`)
Map a website to discover all indexed URLs on the site.
```json theme={null}
{
"name": "firecrawl_map",
"arguments": {
"url": "https://example.com",
"search": "blog",
"sitemap": "include",
"includeSubdomains": false,
"limit": 100,
"ignoreQueryParameters": true
}
}
```
#### Map Tool Options:
* `url`: The base URL of the website to map
* `search`: Optional search term to filter URLs
* `sitemap`: Control sitemap usage - "include", "skip", or "only"
* `includeSubdomains`: Whether to include subdomains in the mapping
* `limit`: Maximum number of URLs to return
* `ignoreQueryParameters`: Whether to ignore query parameters when mapping
**Best for:** Discovering URLs on a website before deciding what to scrape; finding specific sections of a website.
**Returns:** Array of URLs found on the site.
### 3. Search Tool (`firecrawl_search`)
Search the web and optionally extract content from search results.
```json theme={null}
{
"name": "firecrawl_search",
"arguments": {
"query": "your search query",
"limit": 5,
"location": "United States",
"tbs": "qdr:m",
"scrapeOptions": {
"formats": ["markdown"],
"onlyMainContent": true
}
}
}
```
#### Search Tool Options:
* `query`: The search query string (required)
* `limit`: Maximum number of results to return
* `location`: Geographic location for search results
* `tbs`: Time-based search filter (e.g., `qdr:d` for past day, `qdr:w` for past week, `qdr:m` for past month)
* `filter`: Additional search filter
* `sources`: Array of source types to search (`web`, `images`, `news`)
* `scrapeOptions`: Options for scraping search result pages
* `enterprise`: Array of enterprise options (`default`, `anon`, `zdr`)
### 4. Parse Tool (`firecrawl_parse`)
Parse a local file such as a PDF, DOCX, XLSX, or HTML document into clean, LLM-ready data.
```json theme={null}
{
"name": "firecrawl_parse",
"arguments": {
"filePath": "/absolute/path/to/report.pdf",
"formats": ["markdown"]
}
}
```
When you run Firecrawl MCP locally against a Firecrawl API instance with `FIRECRAWL_API_URL`, the MCP server can read `filePath` directly and sends the file bytes to `/v2/parse`.
When you use the remote hosted MCP server, the hosted server cannot read files from your machine. In that case `firecrawl_parse` uses a two-step handoff that also works on the remote keyless URL:
1. Call `firecrawl_parse` with `filePath`. The tool returns a pre-filled upload command and a `nextToolCall` containing an `uploadRef`.
2. Run the upload command on the machine that can read the file, then call `firecrawl_parse` again with the returned `uploadRef`.
The upload command sends the file bytes to a short-lived signed upload target. It does not include your Firecrawl API key.
#### Parse Tool Options:
* `filePath`: Local path to the file you want to parse. Use this for the first call.
* `uploadRef`: Reference returned by the first hosted-MCP call. Use this for the second call after the upload succeeds.
* `formats`: Output formats. Defaults to `markdown`.
* `parsers`: Parser controls, such as PDF parsing options.
* `contentType`: Optional file MIME type override.
* `declaredSizeBytes`: Optional file size hint. Files are limited to 50 MB.
**Best for:** Local or non-public documents that are not available at a public URL.
**Not recommended for:** Public document URLs. Use `firecrawl_scrape` instead; it will detect and parse documents from URLs.
### 5. Crawl Tool (`firecrawl_crawl`)
Start an asynchronous crawl with advanced options.
```json theme={null}
{
"name": "firecrawl_crawl",
"arguments": {
"url": "https://example.com",
"maxDiscoveryDepth": 2,
"limit": 100,
"allowExternalLinks": false,
"deduplicateSimilarURLs": true
}
}
```
### 6. Check Crawl Status (`firecrawl_check_crawl_status`)
Check the status of a crawl job.
```json theme={null}
{
"name": "firecrawl_check_crawl_status",
"arguments": {
"id": "550e8400-e29b-41d4-a716-446655440000"
}
}
```
**Returns:** Status and progress of the crawl job, including results if available.
### 7. Extract Tool (`firecrawl_extract`)
Extract structured information from web pages using LLM capabilities. Supports both cloud AI and self-hosted LLM extraction.
```json theme={null}
{
"name": "firecrawl_extract",
"arguments": {
"urls": ["https://example.com/page1", "https://example.com/page2"],
"prompt": "Extract product information including name, price, and description",
"schema": {
"type": "object",
"properties": {
"name": { "type": "string" },
"price": { "type": "number" },
"description": { "type": "string" }
},
"required": ["name", "price"]
},
"allowExternalLinks": false,
"enableWebSearch": false,
"includeSubdomains": false
}
}
```
Example response:
```json theme={null}
{
"content": [
{
"type": "text",
"text": {
"name": "Example Product",
"price": 99.99,
"description": "This is an example product description"
}
}
],
"isError": false
}
```
#### Extract Tool Options:
* `urls`: Array of URLs to extract information from
* `prompt`: Custom prompt for the LLM extraction
* `schema`: JSON schema for structured data extraction
* `allowExternalLinks`: Allow extraction from external links
* `enableWebSearch`: Enable web search for additional context
* `includeSubdomains`: Include subdomains in extraction
When using a self-hosted instance, the extraction will use your configured LLM. For cloud API, it uses Firecrawl's managed LLM service.
### 8. Agent Tool (`firecrawl_agent`)
Autonomous web research agent that independently browses the internet, searches for information, navigates through pages, and extracts structured data based on your query. This runs asynchronously -- it returns a job ID immediately, and you poll `firecrawl_agent_status` to check when complete and retrieve results.
```json theme={null}
{
"name": "firecrawl_agent",
"arguments": {
"prompt": "Find the top 5 AI startups founded in 2024 and their funding amounts",
"schema": {
"type": "object",
"properties": {
"startups": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": { "type": "string" },
"funding": { "type": "string" },
"founded": { "type": "string" }
}
}
}
}
}
}
}
```
You can also provide specific URLs for the agent to focus on:
```json theme={null}
{
"name": "firecrawl_agent",
"arguments": {
"urls": ["https://docs.firecrawl.dev", "https://firecrawl.dev/pricing"],
"prompt": "Compare the features and pricing information from these pages"
}
}
```
#### Agent Tool Options:
* `prompt`: Natural language description of the data you want (required, max 10,000 characters)
* `urls`: Optional array of URLs to focus the agent on specific pages
* `schema`: Optional JSON schema for structured output
**Best for:** Complex research tasks where you don't know the exact URLs; multi-source data gathering; finding information scattered across the web; extracting data from JavaScript-heavy SPAs that fail with regular scrape.
**Returns:** Job ID for status checking. Use `firecrawl_agent_status` to poll for results.
### 9. Check Agent Status (`firecrawl_agent_status`)
Check the status of an agent job and retrieve results when complete. Poll every 15-30 seconds and keep polling for at least 2-3 minutes before considering the request failed.
```json theme={null}
{
"name": "firecrawl_agent_status",
"arguments": {
"id": "550e8400-e29b-41d4-a716-446655440000"
}
}
```
#### Agent Status Options:
* `id`: The agent job ID returned by `firecrawl_agent` (required)
**Possible statuses:**
* `processing`: Agent is still researching -- keep polling
* `completed`: Research finished -- response includes the extracted data
* `failed`: An error occurred
**Returns:** Status, progress, and results (if completed) of the agent job.
### 10. Interact with a Page (`firecrawl_interact`)
Interact with a page in a live browser session: click buttons, fill forms, extract dynamic content, or navigate deeper.
Use one of two targeting modes:
* Pass `url` to open and interact with a fresh page in one MCP call.
* Pass `scrapeId` from a previous `firecrawl_scrape` call to reuse the already-loaded page.
Do not pass both `url` and `scrapeId`. Provide either `prompt` or `code`. `scrapeOptions` can only be used with `url` mode.
**URL mode example:**
```json theme={null}
{
"name": "firecrawl_interact",
"arguments": {
"url": "https://example.com/products",
"prompt": "Click on the first product and tell me its price"
}
}
```
**Scrape reuse example:**
```json theme={null}
{
"name": "firecrawl_interact",
"arguments": {
"scrapeId": "scrape-id-from-previous-scrape",
"prompt": "Click the Sign In button"
}
}
```
#### Interact Tool Options:
* `url`: Page to interact with; opens the session for you. Use this or `scrapeId`.
* `scrapeId`: Scrape job ID from a previous `firecrawl_scrape` call. Use this or `url`.
* `prompt`: Natural language instruction describing the action to take. Provide `prompt` or `code`.
* `code`: Code to execute in the browser session. Provide `code` or `prompt`.
* `language`: `bash`, `python`, or `node` (optional, defaults to `node`, only used with `code`).
* `timeout`: Execution timeout in seconds, 1–300 (optional, defaults to 30).
* `scrapeOptions`: Optional scrape controls used only with `url` mode.
**Best for:** Multi-step workflows on a single page — searching a site, clicking through results, filling forms, extracting data that requires interaction.
**Returns:** Interaction result including output and live view URLs.
### 11. Stop Interact Session (`firecrawl_interact_stop`)
Stop an interact session for a scraped page. Call this when you are done interacting to free resources.
```json theme={null}
{
"name": "firecrawl_interact_stop",
"arguments": {
"scrapeId": "scrape-id-from-previous-scrape"
}
}
```
#### Interact Stop Options:
* `scrapeId`: The scrape ID for the session to stop (required)
**Returns:** Confirmation that the session has been stopped.
## Logging System
The server includes comprehensive logging:
* Operation status and progress
* Performance metrics
* Credit usage monitoring
* Rate limit tracking
* Error conditions
Example log messages:
```
[INFO] Firecrawl MCP Server initialized successfully
[INFO] Starting scrape for URL: https://example.com
[INFO] Starting crawl for URL: https://example.com
[WARNING] Credit usage has reached warning threshold
[ERROR] Rate limit exceeded, retrying in 2s...
```
## Error Handling
The server provides robust error handling:
* Automatic retries for transient errors
* Rate limit handling with backoff
* Detailed error messages
* Credit usage warnings
* Network resilience
Example error response:
```json theme={null}
{
"content": [
{
"type": "text",
"text": "Error: Rate limit exceeded. Retrying in 2 seconds..."
}
],
"isError": true
}
```
## Development
```bash theme={null}
# Install dependencies
npm install
# Build
npm run build
# Run tests
npm test
```
### Contributing
1. Fork the repository
2. Create your feature branch
3. Run tests: `npm test`
4. Submit a pull request
### Thanks to contributors
Thanks to [@vrknetha](https://github.com/vrknetha), [@cawstudios](https://caw.tech) for the initial implementation!
Thanks to MCP.so and Klavis AI for hosting and [@gstarwd](https://github.com/gstarwd), [@xiangkaiz](https://github.com/xiangkaiz) and [@zihaolin96](https://github.com/zihaolin96) for integrating our server.
## License
MIT License - see LICENSE file for details
1. Open the Agent sidebar in the Editor or the Agent Manager view
2. Click the "..." (More Actions) menu and select **MCP Servers**
3. Select **View raw config** to open your local `mcp_config.json` file
4. Add the following configuration:
```json theme={null}
{
"mcpServers": {
"firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR_FIRECRAWL_API_KEY"
}
}
}
}
```
5. Save the file and click **Refresh** in the Antigravity MCP interface to see the new tools
Replace `YOUR_FIRECRAWL_API_KEY` with your API key from [https://firecrawl.dev/app/api-keys](https://www.firecrawl.dev/app/api-keys).
### Running on n8n
To connect the Firecrawl MCP server in n8n:
1. Get your Firecrawl API key from [https://firecrawl.dev/app/api-keys](https://www.firecrawl.dev/app/api-keys)
2. In your n8n workflow, add an **AI Agent** node
3. In the AI Agent configuration, add a new **Tool**
4. Select **MCP Client Tool** as the tool type
5. Enter the MCP server Endpoint (replace `{YOUR_FIRECRAWL_API_KEY}` with your actual API key):
```
https://mcp.firecrawl.dev/{YOUR_FIRECRAWL_API_KEY}/v2/mcp
```
6. Set **Server Transport** to **HTTP Streamable**
7. Set **Authentication** to **None**
8. For **Tools to include**, you can select **All**, **Selected**, or **All Except** - this will expose the Firecrawl tools (scrape, crawl, map, search, extract, etc.)
For self-hosted deployments, run the MCP server with npx and enable HTTP transport mode:
```bash theme={null}
env HTTP_STREAMABLE_SERVER=true \
FIRECRAWL_API_KEY=fc-YOUR_API_KEY \
FIRECRAWL_API_URL=YOUR_FIRECRAWL_INSTANCE \
npx -y firecrawl-mcp
```
This will start the server on `http://localhost:3000/v2/mcp` which you can use in your n8n workflow as Endpoint. The `HTTP_STREAMABLE_SERVER=true` environment variable is required since n8n needs HTTP transport.
## Configuration
### Environment Variables
#### Cloud and self-hosted API
* `FIRECRAWL_API_KEY`: Your Firecrawl API key
* Required when using cloud API (default)
* Optional when using self-hosted instance with `FIRECRAWL_API_URL`
* `FIRECRAWL_API_URL` (Optional): Custom API endpoint for self-hosted instances
* Example: `https://firecrawl.your-domain.com`
* If not provided, the cloud API will be used (requires API key)
### Configuration Examples
For cloud API usage:
```bash theme={null}
export FIRECRAWL_API_KEY=your-api-key
```
For self-hosted instance:
```bash theme={null}
export FIRECRAWL_API_URL=https://firecrawl.your-domain.com
export FIRECRAWL_API_KEY=your-api-key # If your instance requires auth
```
### Custom configuration with Claude Desktop
Add this to your `claude_desktop_config.json`:
```json theme={null}
{
"mcpServers": {
"mcp-server-firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR_API_KEY_HERE"
}
}
}
}
```
### Hosted MCP vs local MCP
The hosted MCP server is optimized for safe remote use. Some options that are available when running the MCP server locally are narrowed or unavailable remotely:
* Hosted keyless mode exposes only the keyless-supported tools and is rate-limited per IP.
* Local-only file reads are available only when you run the MCP server locally.
* Webhooks and local file paths should be configured from a local or self-hosted MCP server when the agent needs access to local resources.
### Rate Limiting
Rate limits are enforced by Firecrawl. Use an API key for higher limits and access to the full tool set.
## Available Tools
### 1. Scrape Tool (`firecrawl_scrape`)
Scrape content from a single URL with advanced options.
```json theme={null}
{
"name": "firecrawl_scrape",
"arguments": {
"url": "https://example.com",
"formats": ["markdown"],
"onlyMainContent": true,
"waitFor": 1000,
"mobile": false,
"includeTags": ["article", "main"],
"excludeTags": ["nav", "footer"],
"skipTlsVerification": false
}
}
```
To redact personally identifiable information, include `redactPII` in the scrape tool arguments.
```json theme={null}
{
"name": "firecrawl_scrape",
"arguments": {
"url": "https://example.com/contact",
"formats": ["markdown"],
"redactPII": true
}
}
```
### 2. Map Tool (`firecrawl_map`)
Map a website to discover all indexed URLs on the site.
```json theme={null}
{
"name": "firecrawl_map",
"arguments": {
"url": "https://example.com",
"search": "blog",
"sitemap": "include",
"includeSubdomains": false,
"limit": 100,
"ignoreQueryParameters": true
}
}
```
#### Map Tool Options:
* `url`: The base URL of the website to map
* `search`: Optional search term to filter URLs
* `sitemap`: Control sitemap usage - "include", "skip", or "only"
* `includeSubdomains`: Whether to include subdomains in the mapping
* `limit`: Maximum number of URLs to return
* `ignoreQueryParameters`: Whether to ignore query parameters when mapping
**Best for:** Discovering URLs on a website before deciding what to scrape; finding specific sections of a website.
**Returns:** Array of URLs found on the site.
### 3. Search Tool (`firecrawl_search`)
Search the web and optionally extract content from search results.
```json theme={null}
{
"name": "firecrawl_search",
"arguments": {
"query": "your search query",
"limit": 5,
"location": "United States",
"tbs": "qdr:m",
"scrapeOptions": {
"formats": ["markdown"],
"onlyMainContent": true
}
}
}
```
#### Search Tool Options:
* `query`: The search query string (required)
* `limit`: Maximum number of results to return
* `location`: Geographic location for search results
* `tbs`: Time-based search filter (e.g., `qdr:d` for past day, `qdr:w` for past week, `qdr:m` for past month)
* `filter`: Additional search filter
* `sources`: Array of source types to search (`web`, `images`, `news`)
* `scrapeOptions`: Options for scraping search result pages
* `enterprise`: Array of enterprise options (`default`, `anon`, `zdr`)
### 4. Parse Tool (`firecrawl_parse`)
Parse a local file such as a PDF, DOCX, XLSX, or HTML document into clean, LLM-ready data.
```json theme={null}
{
"name": "firecrawl_parse",
"arguments": {
"filePath": "/absolute/path/to/report.pdf",
"formats": ["markdown"]
}
}
```
When you run Firecrawl MCP locally against a Firecrawl API instance with `FIRECRAWL_API_URL`, the MCP server can read `filePath` directly and sends the file bytes to `/v2/parse`.
When you use the remote hosted MCP server, the hosted server cannot read files from your machine. In that case `firecrawl_parse` uses a two-step handoff that also works on the remote keyless URL:
1. Call `firecrawl_parse` with `filePath`. The tool returns a pre-filled upload command and a `nextToolCall` containing an `uploadRef`.
2. Run the upload command on the machine that can read the file, then call `firecrawl_parse` again with the returned `uploadRef`.
The upload command sends the file bytes to a short-lived signed upload target. It does not include your Firecrawl API key.
#### Parse Tool Options:
* `filePath`: Local path to the file you want to parse. Use this for the first call.
* `uploadRef`: Reference returned by the first hosted-MCP call. Use this for the second call after the upload succeeds.
* `formats`: Output formats. Defaults to `markdown`.
* `parsers`: Parser controls, such as PDF parsing options.
* `contentType`: Optional file MIME type override.
* `declaredSizeBytes`: Optional file size hint. Files are limited to 50 MB.
**Best for:** Local or non-public documents that are not available at a public URL.
**Not recommended for:** Public document URLs. Use `firecrawl_scrape` instead; it will detect and parse documents from URLs.
### 5. Crawl Tool (`firecrawl_crawl`)
Start an asynchronous crawl with advanced options.
```json theme={null}
{
"name": "firecrawl_crawl",
"arguments": {
"url": "https://example.com",
"maxDiscoveryDepth": 2,
"limit": 100,
"allowExternalLinks": false,
"deduplicateSimilarURLs": true
}
}
```
### 6. Check Crawl Status (`firecrawl_check_crawl_status`)
Check the status of a crawl job.
```json theme={null}
{
"name": "firecrawl_check_crawl_status",
"arguments": {
"id": "550e8400-e29b-41d4-a716-446655440000"
}
}
```
**Returns:** Status and progress of the crawl job, including results if available.
### 7. Extract Tool (`firecrawl_extract`)
Extract structured information from web pages using LLM capabilities. Supports both cloud AI and self-hosted LLM extraction.
```json theme={null}
{
"name": "firecrawl_extract",
"arguments": {
"urls": ["https://example.com/page1", "https://example.com/page2"],
"prompt": "Extract product information including name, price, and description",
"schema": {
"type": "object",
"properties": {
"name": { "type": "string" },
"price": { "type": "number" },
"description": { "type": "string" }
},
"required": ["name", "price"]
},
"allowExternalLinks": false,
"enableWebSearch": false,
"includeSubdomains": false
}
}
```
Example response:
```json theme={null}
{
"content": [
{
"type": "text",
"text": {
"name": "Example Product",
"price": 99.99,
"description": "This is an example product description"
}
}
],
"isError": false
}
```
#### Extract Tool Options:
* `urls`: Array of URLs to extract information from
* `prompt`: Custom prompt for the LLM extraction
* `schema`: JSON schema for structured data extraction
* `allowExternalLinks`: Allow extraction from external links
* `enableWebSearch`: Enable web search for additional context
* `includeSubdomains`: Include subdomains in extraction
When using a self-hosted instance, the extraction will use your configured LLM. For cloud API, it uses Firecrawl's managed LLM service.
### 8. Agent Tool (`firecrawl_agent`)
Autonomous web research agent that independently browses the internet, searches for information, navigates through pages, and extracts structured data based on your query. This runs asynchronously -- it returns a job ID immediately, and you poll `firecrawl_agent_status` to check when complete and retrieve results.
```json theme={null}
{
"name": "firecrawl_agent",
"arguments": {
"prompt": "Find the top 5 AI startups founded in 2024 and their funding amounts",
"schema": {
"type": "object",
"properties": {
"startups": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": { "type": "string" },
"funding": { "type": "string" },
"founded": { "type": "string" }
}
}
}
}
}
}
}
```
You can also provide specific URLs for the agent to focus on:
```json theme={null}
{
"name": "firecrawl_agent",
"arguments": {
"urls": ["https://docs.firecrawl.dev", "https://firecrawl.dev/pricing"],
"prompt": "Compare the features and pricing information from these pages"
}
}
```
#### Agent Tool Options:
* `prompt`: Natural language description of the data you want (required, max 10,000 characters)
* `urls`: Optional array of URLs to focus the agent on specific pages
* `schema`: Optional JSON schema for structured output
**Best for:** Complex research tasks where you don't know the exact URLs; multi-source data gathering; finding information scattered across the web; extracting data from JavaScript-heavy SPAs that fail with regular scrape.
**Returns:** Job ID for status checking. Use `firecrawl_agent_status` to poll for results.
### 9. Check Agent Status (`firecrawl_agent_status`)
Check the status of an agent job and retrieve results when complete. Poll every 15-30 seconds and keep polling for at least 2-3 minutes before considering the request failed.
```json theme={null}
{
"name": "firecrawl_agent_status",
"arguments": {
"id": "550e8400-e29b-41d4-a716-446655440000"
}
}
```
#### Agent Status Options:
* `id`: The agent job ID returned by `firecrawl_agent` (required)
**Possible statuses:**
* `processing`: Agent is still researching -- keep polling
* `completed`: Research finished -- response includes the extracted data
* `failed`: An error occurred
**Returns:** Status, progress, and results (if completed) of the agent job.
### 10. Interact with a Page (`firecrawl_interact`)
Interact with a page in a live browser session: click buttons, fill forms, extract dynamic content, or navigate deeper.
Use one of two targeting modes:
* Pass `url` to open and interact with a fresh page in one MCP call.
* Pass `scrapeId` from a previous `firecrawl_scrape` call to reuse the already-loaded page.
Do not pass both `url` and `scrapeId`. Provide either `prompt` or `code`. `scrapeOptions` can only be used with `url` mode.
**URL mode example:**
```json theme={null}
{
"name": "firecrawl_interact",
"arguments": {
"url": "https://example.com/products",
"prompt": "Click on the first product and tell me its price"
}
}
```
**Scrape reuse example:**
```json theme={null}
{
"name": "firecrawl_interact",
"arguments": {
"scrapeId": "scrape-id-from-previous-scrape",
"prompt": "Click the Sign In button"
}
}
```
#### Interact Tool Options:
* `url`: Page to interact with; opens the session for you. Use this or `scrapeId`.
* `scrapeId`: Scrape job ID from a previous `firecrawl_scrape` call. Use this or `url`.
* `prompt`: Natural language instruction describing the action to take. Provide `prompt` or `code`.
* `code`: Code to execute in the browser session. Provide `code` or `prompt`.
* `language`: `bash`, `python`, or `node` (optional, defaults to `node`, only used with `code`).
* `timeout`: Execution timeout in seconds, 1–300 (optional, defaults to 30).
* `scrapeOptions`: Optional scrape controls used only with `url` mode.
**Best for:** Multi-step workflows on a single page — searching a site, clicking through results, filling forms, extracting data that requires interaction.
**Returns:** Interaction result including output and live view URLs.
### 11. Stop Interact Session (`firecrawl_interact_stop`)
Stop an interact session for a scraped page. Call this when you are done interacting to free resources.
```json theme={null}
{
"name": "firecrawl_interact_stop",
"arguments": {
"scrapeId": "scrape-id-from-previous-scrape"
}
}
```
#### Interact Stop Options:
* `scrapeId`: The scrape ID for the session to stop (required)
**Returns:** Confirmation that the session has been stopped.
## Logging System
The server includes comprehensive logging:
* Operation status and progress
* Performance metrics
* Credit usage monitoring
* Rate limit tracking
* Error conditions
Example log messages:
```
[INFO] Firecrawl MCP Server initialized successfully
[INFO] Starting scrape for URL: https://example.com
[INFO] Starting crawl for URL: https://example.com
[WARNING] Credit usage has reached warning threshold
[ERROR] Rate limit exceeded, retrying in 2s...
```
## Error Handling
The server provides robust error handling:
* Automatic retries for transient errors
* Rate limit handling with backoff
* Detailed error messages
* Credit usage warnings
* Network resilience
Example error response:
```json theme={null}
{
"content": [
{
"type": "text",
"text": "Error: Rate limit exceeded. Retrying in 2 seconds..."
}
],
"isError": true
}
```
## Development
```bash theme={null}
# Install dependencies
npm install
# Build
npm run build
# Run tests
npm test
```
### Contributing
1. Fork the repository
2. Create your feature branch
3. Run tests: `npm test`
4. Submit a pull request
### Thanks to contributors
Thanks to [@vrknetha](https://github.com/vrknetha), [@cawstudios](https://caw.tech) for the initial implementation!
Thanks to MCP.so and Klavis AI for hosting and [@gstarwd](https://github.com/gstarwd), [@xiangkaiz](https://github.com/xiangkaiz) and [@zihaolin96](https://github.com/zihaolin96) for integrating our server.
## License
MIT License - see LICENSE file for details